消息队列-RabbitMQ
今天我们说一下消息队列MQ:MQ的定义是什么?MQ使用场合有哪些
MQ定义:消息队列的目的是为了实现各个APP之间的通讯,APP基于MQ实现消息的发送和接收实现程序之间的通讯,只要多个应用程序就可以运行在不同的主机上,通过MQ就可以实现夸网络通讯,因此MQ实现了业务的解耦和异步机制。异步:客户端发送消息后去处理其他时间。同步:客户端发送消息后一直等待返回值
MQ使用场合:消息队列作为高并发系统的核心组件之一,能够帮助业务系统结构提升开发效率和系统稳定性,消息队列主要具有以下特点:
削峰填谷:主要解决瞬时写压力大于应用服务能力导致消息丢失,系统崩溃等问题
系统解耦:解决不同程度、不同能力级别系统之间依赖导致一死全死
提升性能:当存在一对多调用时,可以发送一条消息给消息系统,让消息系统通知相关系统
蓄流压测:线上有些链路不好压测,可以通过堆积一定数量消息在开发来压测
MQ的介绍
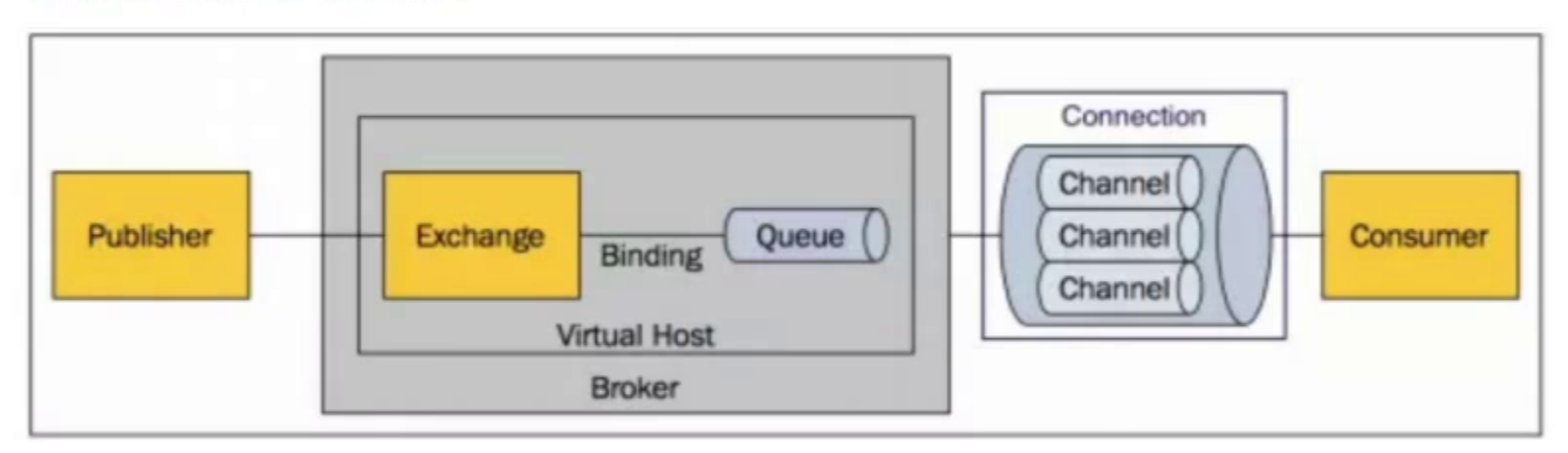
- Broker:接收和分发消息的应用,RabbitMQ server 就是Message Broker
- Virtual host:相当于MQ里面的一个交换机,一个MQ有多个应用使用,创建Virtual host在每个V host中创建路由和队列,将路由绑定对应的队列中,一个MQ中有多个V host
- Connection:生产者、消费者、和broker之间的TCP连接
- channel:如果每次访问RabbitMQ都简历一个connection,在消息量大的时候建立TCP连接开销将是很大的,效率也低,channel是在connection内部建立逻辑连接,如果应用程序支持多线程, 通常每个应用创建单独的channel进行通讯
- Virtual host:相当于MQ里面的一个交换机,一个MQ有多个应用使用,创建Virtual host在每个V host中创建路由和队列,将路由绑定对应的队列中,一个MQ中有多个V host,AMQP的基本组件划分到一个虚拟的分组中
- Connection:生产者、消费者、和broker之间的TCP连接
- channel:如果每次访问RabbitMQ都简历一个connection,在消息量大的时候建立TCP连接开销将是很大的,效率也低,channel是在connection内部建立逻辑连接,如果应用程序支持多线程, 通常每个应用创建单独的channel进行通讯,AMQP method包含了channel id帮助客户端和message broker识别channel,所以每个channel之间都是完全隔离的
- Exchange:message到达broker的第一站,根据分发规则,匹配查询表中的routingkey,分发到消息queue中
- Queue:消息最重被送到这里等到consumer取走
- Binding:exchange和queue之间的虚拟连接,binding中可以包含routing key
RabbitMQ优势:具有高并发优点、支持分布式、具有消息确认机制、消息持久化机制,消息可靠性和集群可靠性高
Queue的特性:消息基于先进先出的原则进行顺序消费、消息可以持久化到磁盘节点服务器、消息可以缓存到内存节点服务器提高性能
RabbitMQ流程

生产者发送消息到Broker(RabbitMQ)在Broker内部,用户创建Exchange/Queue,通过Binding规则将两者联系到一起,Exchange分发消息,根据类型/binding的不同分发策略有区别,消息醉后来到Queue中,等待消费者取走
RabbitMQ集群分为两种方式:
- 普通模式:创建好MQ集群后默认模式,生产者把消息写入期中一个MQ中,那么其他集群内的节点只有相同的元数据(类似于数据存在哪个节点、创建的时间等)如果消费者去访问第一次没有写入数据的MQ中,他会根据元数据拉取数据。该模式有一个问题就是当第一次写入数据的节点故障后,其它节点无法从有数据节点的MQ中取到数据
- 镜像集群模式:需要把队列做成镜像队列,存在与多个节点,属于RabbitMQ的高可用方案。生产者把数据写入集群中任意一个节点内,节点写入成功后会主动推送给其它节点进行同步信息。该模式的缺点为如果数据过大则会有网络IO延迟。可以使用两个节点为内存写入,一个节点为磁盘写入做持久化,只开放两个内存节点给予生产者访问和写入。
集群中有两种节点类型:
- 内存节点:只将数据写入内存中
- 磁盘节点:保存数据到内存和磁盘
- 内存节点虽然不写入磁盘,但是它执行比磁盘节点要号,集群中只需要一个磁盘节点来保存数据就足够了如果集群中只有内存节点,那么不能全部停止他们,否则所有数据消息在服务器全部停止后都会丢失。