今天给大家浅讲一下ELK,ELK 是由 Elasticsearch、Logstash、Kibana 三个开源软件的组成的 一个组合体,ELK 是 elastic 公司研发的一套完整的日志收集、分析和展示的企业 级解决方案,ELK stack 的主要优点有如下几个:
处理方式灵活: elasticsearch 是实时全文索引,具有强大的搜索功能
配置相对简单:elasticsearch 的 API 全部使用 JSON 接口,logstash 使用模块配 置,kibana 的配置文件部分更简单。
检索性能高效:基于优秀的设计,虽然每次查询都是实时,但是也可以达到百 亿级数据的查询秒级响应。
集群线性扩展:elasticsearch 和 logstash 都可以灵活线性扩展 前端操作绚丽:kibana 的前端设计比较绚丽,而且操作简单
什么是elasticsearch?
是一个高度可扩展的开源全文搜索和分析引擎,它可实现数据的实时全文搜索 搜索、支持分布式可实现高可用、提供 API 接口,可以处理大规模日志数据,比 如 Nginx、Tomcat、系统日志等功能。
Elasticsearch 使用 Java 语言开发,是建立在全文搜索引擎 Apache Lucene 基础 之上的搜索引擎,https://lucene.apache.org/。
Elasticsearch 的特点: 实时搜索、实时分析 分布式架构、实时文件存储 文档导向,所有对象都是文档 高可用,易扩展,支持集群,分片与复制
什么是logstash?
Logstash 是一个具有实时传输能力的数据收集引擎,其可以通过插件实现日志 收集和转发,支持日志过滤,支持普通 log、自定义 json 格式的日志解析,最终 把经过处理的日志发送给 elasticsearch。
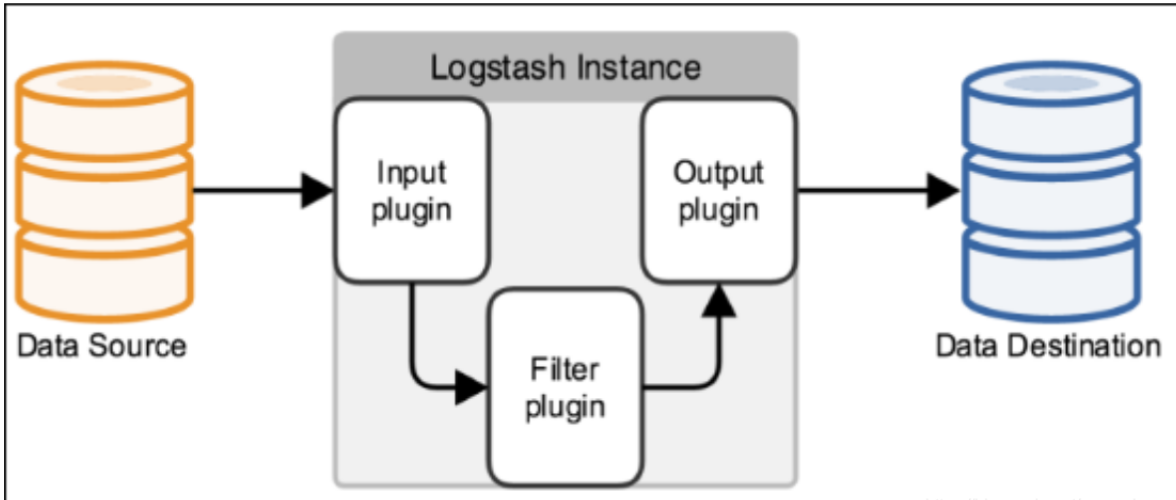
什么是kibana?
Kibana 为 elasticsearch 提供一个查看数据的web界面,其主要是通过 elasticsearch 的 API 接口进行数据查找,并进行前端数据可视化的展现,另外还 可以针对特定格式的数据生成相应的表格、柱状图、饼图等。
下面我们开始按照下面图中架构来搭建ELK环境
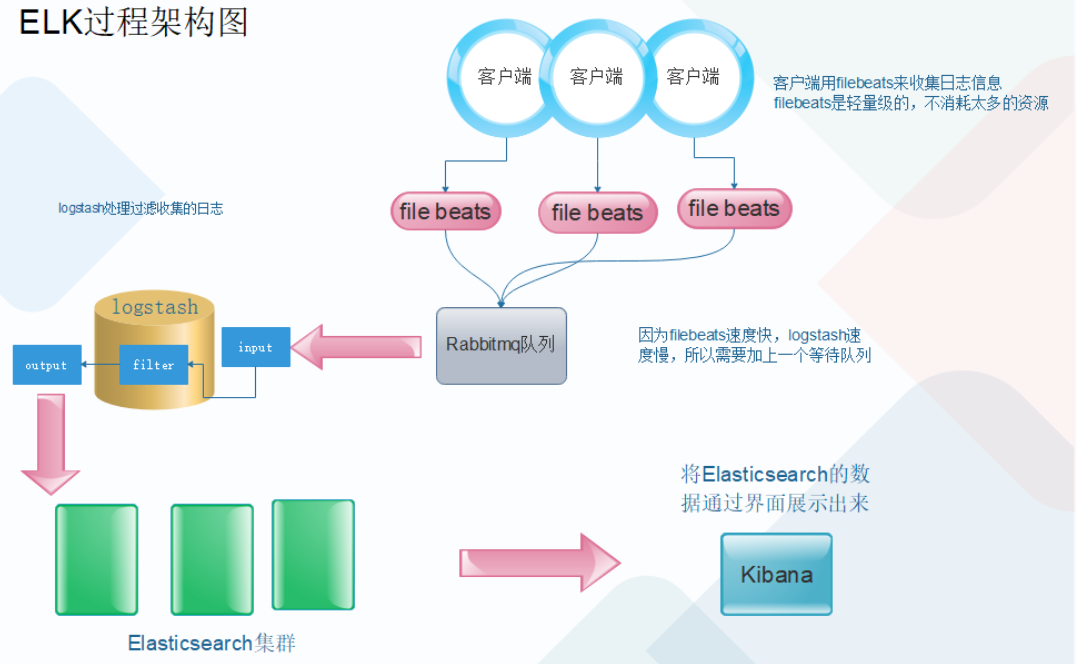
本次elasticsearch使用三个节点版本号7.12.1 系统为Ubuntu 18.04 节点ip为: 10.0.0.120 es1 10.0.0.121 es2 10.0.0.122 es3 一、首先elasticsearch需要java环境本次安装使用java-11.0.15 查看合适的JDK环境 # apt install openjdk-11-jre 二、添加数据盘 mkdir /data/esdata -p #创建数据存放位置 mkfs.ext4 /dev/sdb #格式化磁盘 mount /dev/sdb /data/esdata #挂载到数据存放位置 vim /etc/fstab #加入开机启动挂载 /dev/sdb /data/esdata ext4 defaulst 0 0 mount -a #重新加载fstab文件,是否正常挂载 三、安装elasticsearch (本次在清华源下载) # wget https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/apt/pool/main/e/elasticsearch/elasticsearch-7.12.1-amd64.deb # dpkg -i elasticsearch-7.12.1-amd64.deb 四、配置elasticsearch集群 # cat /etc/elasticsearch/elasticsearch.yml |grep -v ^# cluster.name: lhl-es #集群名称,集群名称必须统一 node.name: node1 #每个elasticsearch节点名称都不能唯一 path.data: /data/esdata/elasticsearch #存储数据目录 path.logs: /data/esdata/logs #存储日志目录 network.host: 10.0.0.120 #监听地址 http.port: 9200 #监听端口 discovery.seed_hosts: ["10.0.0.120", "10.0.0.121", "10.0.0.122"] #集群内所有节点的ip cluster.initial_master_nodes: ["10.0.0.120", "10.0.0.121", "10.0.0.122"] #可以选举为master节点的IP action.destructive_requires_name: true #调用API删除索引必须指定库名称,以防*删除所有库 http.cors.enabled: true #开启支持跨域访问 http.cors.allow-origin: "*" #指定允许访问范围 五、给数据目录权限 # chown -R elasticsearch.elasticsearch /data/esdata 六、启动服务,查看监听端口:9200客户端 9300集群 # systemctl start elasticsearch.service # systemctl enable elasticsearch.service 七、解除elasticsearch内存使用限制,默认限制为4G,内存限制根据系统内存的总数的一般,最大不超过30G,如果主机内存为80G,建议新建一个elasticsearch节点。 vim /etc/elasticsearch/elasticsearch.yml bootstrap.memory_lock: true #初始化内存的锁定,启动时直接占用限制的内存数量 vim /usr/lib/systemd/system/elasticsearch.service #修改内存限制 LimitMEMLOCK=infinity #无限制使用内存 vim /etc/elasticsearch/jvm.options 修改限制的内存大小 22 -Xms2g 23 -Xmx2g 然后在重启服务
es数据分片
ES 的每个分片(shard)都是lucene的一个index,而lucene的一个index只能存储20亿个文档,所以一个分片也只能最多存储20亿个文档。 另外,我们也建议一个分片的大小在10G-50G之间,太大的话查询时会比较慢,另外在做副本修复的时,耗时比较多;分片太小的话,会导致一个索引的分片数目很多,查询时带来的fanin-fanout 太大。
分片数量:elasticsearch 7版本是默认一主分片,一个副本 分片数量最好不超过node节点数量。
集群中如果有一个节点挂掉,副本转成主分片,在另外节点创建副本。
Master 的职责: 统计各 node 节点状态信息、集群状态信息统计、索引的创建和删除、索引分配 的管理、关闭 node 节点等
Slave 的职责:从 master 同步数据、等待机会成为 Master
一个文件写入后会把数据拆分为配置分片的数量,同时写入,比如有三个分片,6G文件拆分为三分,每份2G写入不同的分片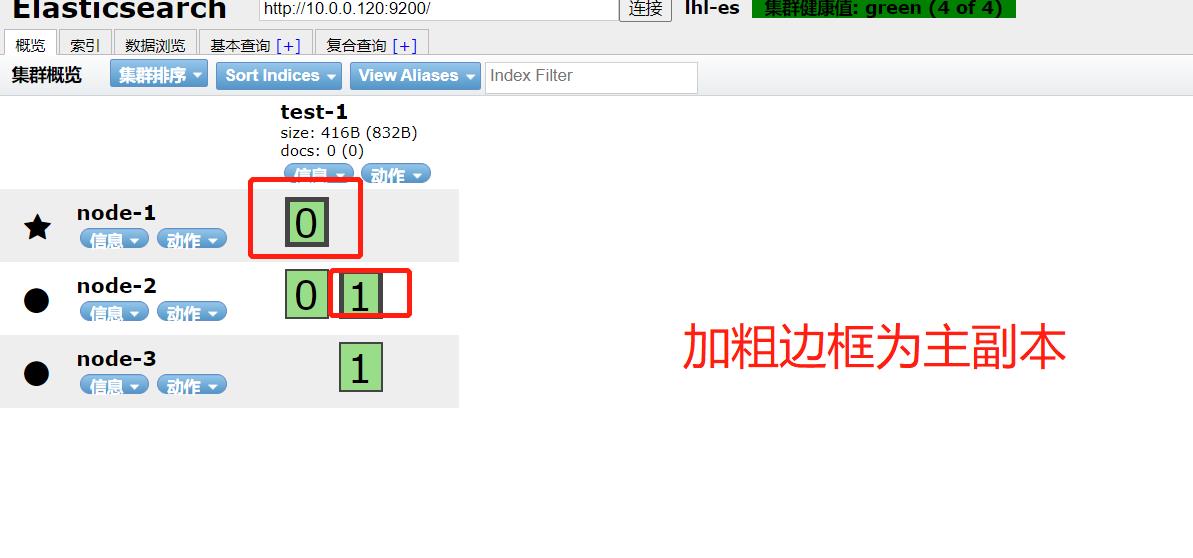
es集群监控
curl -sXGET http://10.0.0.120:9200/_cluster/health?pretty=true
{
"cluster_name" : "lhl-es",
"status" : "yellow", #yellow为副本分片丢失 red为主分片丢失 gree为运行正常
"timed_out" : false,
"number_of_nodes" : 2,
"number_of_data_nodes" : 2,
"active_primary_shards" : 2,
"active_shards" : 2,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 2,
"delayed_unassigned_shards" : 2,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 50.0
}
#获取到的是一个 json 格式的返回值,那就可以通过shell的if判断对其中的信息进行分 析,例如对 status 进行分析,如果等于 green(绿色)就是运行在正常,等于 yellow(黄 色)表示副本分片丢失,red(红色)表示主分片丢失