今天来讲一下k8s中pod是如何动态增加或缩减pod副本数,平常我们指定一个pod的副本数都是在deployment中replicas值来固化副本数,但是如果突然一段时间业务访问量加大,pod的资源使用率变高或者撑爆服务会导致pod挂掉,当然你也可以通过压测来判断你这套系统的最大处理能力,经过压测后服务最大处理能力后在增加几个副本数,但是增加这几个副本数是一个资源的浪费,因此我们可以使用HPA动态的根据pod的使用资源状态来扩容或者缩容,比如HPA发现某个监控的deployment的cpu使用率大于HPA所设定的值,就会调用deployment增加一个副本数,如果小于所设定的值就会减少副本数
工作流程
通过Metrices Server组件完成数据采集,然后将采集后的数据通过API(Aggregated API,汇总API),例如metrics.k8s.io、custom.metrics.k8s.io、external.metrics.k8s.io,发送给HPA控制器进行查询,如果超过或者低于设定的值HPA会发送指令到Deployment控制器开始缩扩容pod
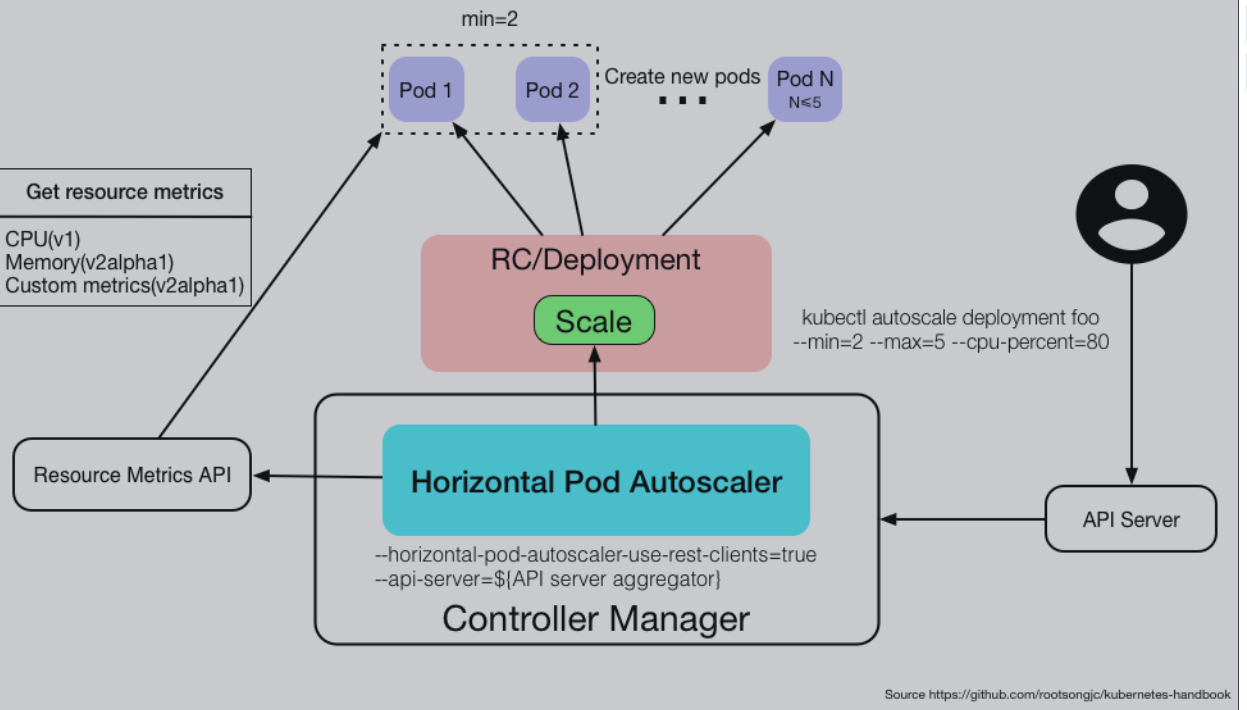
如何配置伸缩pod
首先需要部署Metrices Server
本次下载为0.4.4版本https://github.com/kubernetes-sigs/metrics-server/releases
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
name: system:aggregated-metrics-reader
rules:
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- pods
- nodes
- nodes/stats
- namespaces
- configmaps
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
ports:
- name: https
port: 443
protocol: TCP
targetPort: https
selector:
k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
image: k8s.gcr.io/metrics-server/metrics-server:v0.4.4
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
ports:
- containerPort: 4443
name: https
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: https
scheme: HTTPS
periodSeconds: 10
securityContext:
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
volumeMounts:
- mountPath: /tmp
name: tmp-dir
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir: {}
name: tmp-dir
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100
验证Metrices Server 是否生效
kubectl top node #可以看到node节点的资源使用率说明成功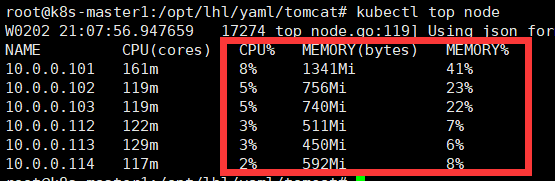
配置controller-manager参数以下几点 注:根据公司环境来盘点是否配置
# kube-controller-manager --help | grep horizontal-pod-autoscaler-sync-period
--horizontal-pod-autoscaler-sync-period duration The period for syncing the number of pods in horizontal pod autoscaler. (default 15s)
#定义pod数量水平伸缩的间隔周期,默认15秒
--horizontal-pod-autoscaler-cpu-initialization-period duration The period after pod start when CPU samples might be skipped. (default 5m0s)
#用于设置 pod 的初始化时间, 在此时间内的 pod,CPU 资源指标将不会被采纳,默认为5分钟
--horizontal-pod-autoscaler-initial-readiness-delay duration The period after pod start during which readiness changes will be treated as initial readiness. (default 30s)
#用于设置 pod 准备时间, 在此时间内的 pod 统统被认为未就绪及不采集数据,默认为30秒
根据环境更改service文件
# vim /etc/systemd/system/kube-controller-manager.service 写入service文件中
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
[Service]
ExecStart=/usr/bin/kube-controller-manager \
--bind-address=10.0.0.101 \
--allocate-node-cidrs=true \
--cluster-cidr=10.200.0.0/16 \
--cluster-name=kubernetes \
--cluster-signing-cert-file=/etc/kubernetes/ssl/ca.pem \
--cluster-signing-key-file=/etc/kubernetes/ssl/ca-key.pem \
--kubeconfig=/etc/kubernetes/kube-controller-manager.kubeconfig \
--leader-elect=true \
--node-cidr-mask-size=24 \
--root-ca-file=/etc/kubernetes/ssl/ca.pem \
--service-account-private-key-file=/etc/kubernetes/ssl/ca-key.pem \
--service-cluster-ip-range=10.100.0.0/16 \
--use-service-account-credentials=true \
--horizontal-pod-autoscaler-use-rest-clients=true \ #是否使用其他客户端数据
--horizontal-pod-autoscaler-sync-period=10s \
--v=2
Restart=always
RestartSec=5
[Install]
WantedBy=multi-user.target重启controller-manager 验证以上参数是否生效

1、手动扩容
可以根据业务的高峰期来手动进行扩容,比如早上八点访问业务量高,那就写一个定时任务进行扩容
kubectl scale deployment/deploymentname --replicas=2 -nlhl #把副本数调整为2
kubectl autoscale deployment/bhb-tomcat --min=2 --max=5 --cpu-percent=80 -nlhl #副本数最大为5 最小为2 cpu超过80%2、编写yaml文件进行自动扩容
#apiVersion: autoscaling/v2beta1
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
namespace: lhl
name: tomcat-hpa #hpa的名称
labels:
app: tomcat-app1
version: v2beta1
spec:
scaleTargetRef:
apiVersion: apps/v1
#apiVersion: extensions/v1beta1
kind: Deployment #通过deployment来管理
name: bhb-tomcat #管理那个deployment的名称
minReplicas: 2 #最小副本数
maxReplicas: 20 #最大副本数
targetCPUUtilizationPercentage: 60 #定义扩容CPU的指标
#metrics: #早期写法
#- type: Resource
# resource:
# name: cpu
# targetAverageUtilization: 60
#- type: Resource
# resource:
# name: memory